National Web Studies: Mapping Iran Online
Richard Rogers, Esther Weltevrede, Sabine Niederer and Erik Borra
The research inquires into the liveliness of the Iranian web in times of censorship as well as oppression of voices critical to the regime. It offers a general approach to studying a "national web," and its health, by measuring the freshness and responsiveness of websites significant to a particular country. It also inquires into the effects of censorship in Iran on (critical) content production, with the lead question being whether censorship kills content. We have found an Iranian web that is fresh and responsive, despite widespread blockage of key websites. Secondly, we have found indications of routine censorship circumvention by Iranian web users. Finally, for the period of study (2009-2011), language critical of the regime continues to be published online, and its incidence has risen over time.
The work offers an approach to conceptualizing, demarcating and analyzing a national web. Instead of defining a priori the types of websites to be included in a national web, the approach put forward here makes use of web devices (platforms and engines) that purport to provide (ranked) lists of URLs relevant to a particular country. Once gathered in such a manner, the websites are studied for their properties, following certain of the common measures (such as responsiveness and page age), and repurposing them to speak in terms of the health of a national web. Are sites lively, or neglected? The case study in question is Iran, which is special for the degree of Internet censorship undertaken by the state. Despite the widespread censorship, we have found a highly responsive Iranian web. We also report on the relationship between responsiveness and blockage, i.e., whether blocked sites are still up, and also whether they have been recently updated. Blocked yet blogging, portions of the Iranian web show strong indications of an active Internet censorship circumvention culture. In seeking to answer, additionally, whether censorship has killed content, a textual analysis shows continued use of language considered critical by the regime, thereby indicating a dearth of self-censorship, at least for websites that are recommended by the leading Iranian platform, Balatarin. The study concludes with the general implications of the approach put forward for national web studies, including a description of the benefits of a national web health index.
We would like to thank the Iran Media Program at the Annenberg School for Communication, University of Pennsylvania, for supporting the work, and Mahmood Enayat for his thoughtful commentary. We also would like to thank the Iranian web culture expert, Ebby Sharifi, who gathered with us at the Annenberg School for the Mapping Online Culture workshop in May 2011 and Cameran Ashraf, Bronwen Robertson, Leva Zand and Niaz Zarrinbakhsh who participated in the 2011 Digital Methods Summer School at the University of Amsterdam. Special thanks to the technical team at the Citizen Lab, University of Toronto, for reviewing the contents of this study.
Authors
Richard Rogers, PhD holds the Chair and is University Professor in New Media & Digital Culture at the University of Amsterdam. He is director of the Govcom.org Foundation and the Digital Methods Initiative, Amsterdam. Esther Weltevrede, Erik Borra and Sabine Niederer are affiliates of the Govcom.org Foundation, and Weltevrede and Niederer coordinate the Digital Methods Initiative, where Borra is the lead programmer. They also are pursuing PhDs in New Media & Digital Culture, University of Amsterdam.
The Govcom.org Foundation is dedicated to the creation and hosting of info-political tools for the web, including the Issue Crawler, the network location, analysis and visualization software at http://www.issuecrawler.net/. Reworking method for Internet-related research, the Digital Methods Initiative (DMI), Amsterdam, is a joint initiative of Govcom.org and the University of Amsterdam. DMI is online at http://www.digitalmethods.net/.
To access the data, you should apply for an account to the Issue Crawler, the network location, analysis and visualization software by the Govcom.org Foundation, Amsterdam. To apply for an account, please visit the Issue Crawler registration page, and register as an "academic" user, providing your university email account.
URL lists
We first turned to web devices (platforms and engines) to provide (ranked) lists of relevant URLs. The queried devices are Alexa, Donbaleh, Sabzlink, Google web and region search, Google Ad Planner, Likekhor and Balatarin. As devices such as Alexa only provide a ranked list of hosts, we chopped all urls to their (sub-)domain part, in order to facilitate comparison. The data were collected on 7 July 2011 and resulted in a list of URLs per web device. For a more elaborate discussion of the selection of URLs, see the section “Device cultures: How websites are valued, and ranked”. The data file containing the URL lists has one column with URLs and one column with the device which returned the URLs.
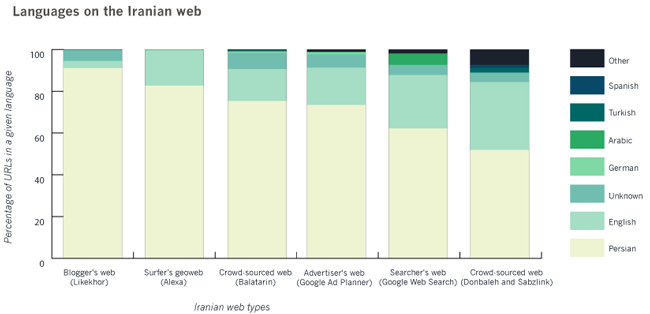
Languages
To automatically detect the different languages used in the Iranian webs, we used a custom tool that makes use of AlchemyAPI. The data file with languages per web contains three columns: URLs, the (primary) language of that URL, the device which returned the URL. For more information, see the section “The Iranian web and its languages”.
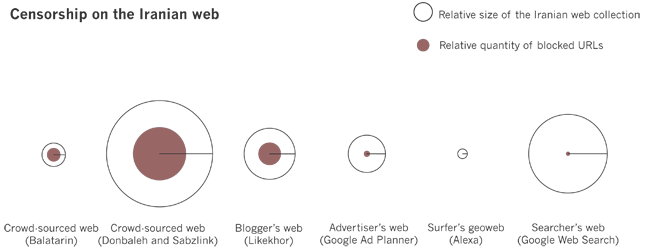
Proxy results
In order to test for censorship we ran all the URLs retrieved from the web devices through proxies located in Iran. To obtain a list of proxies in Iran we did a web search for ‘free proxy lists’ and we made sure to have a diverse range of proxies, located in different cities and in the IP-range of different ISPs. For more detail, see the section in the paper on ‘The Iranian webs and Internet censorship’.
We provide two data files. The first data file with raw test data for the proxies contains the following columns: IP-address and port of the proxy, the proxy ID, the ID of the tested URL, the date and time of the check, the HTTP response code returned by the proxy, the tested URL, the device from which we extracted the URL. The raw test data was aggregated into the proxy analysis data file, containing the following columns: URL, the device from wich we extracted the URL, the HTTP response code for that URL when queried from the Netherlands, the amount of proxies returning the same HTTP response code for the URL, the amount of proxies through which the URL was queried, the HTTP response code returned by more than half of the proxies (-1 if there was no majority), whether the response of the majority of proxies was the same as for the test in the Netherlands.
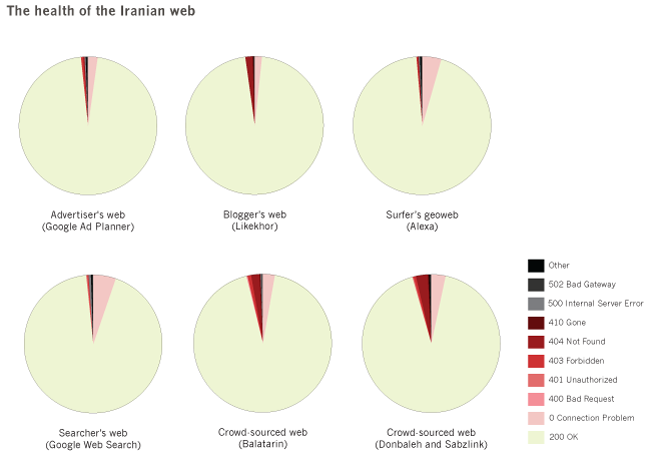
Responsiveness
For the section on ‘The Iranian webs and responsiveness’ we used the third column (the HTTP response code for a URL when queried from the Netherlands) from the proxy analysis data file previously mentioned
Freshness
Apart from the responsiveness test, we wanted to find out whether the URLs are active. Is the content on the websites fresh? We are studying a subset of the webs — the blocked sites in the crowd-sourced (Balatarin, Donbaleh and Sabzlink) and the blogger’s webs (Likekhor).
To determine how fresh these sites are, for each host (per Web device) we ask the Google feed API whether each site has a feed (e.g., RSS or atom). If it does, we parse the feed with the Python Universal Feed Parser library and extract the date of the latest post.
The resulting timestamp analysis data file contains the following columns: the checked URL, the link of the feed, the date of the latest post, the unix timestamp of that date. If no feed was found, it was checked whether a Last-Modfiied HTTP header could be found. If so, that timestamp was inserted in the timestamp analysis file. For the paper, only the dates were used when a feed was detected.
For more info see the section on ‘the Iranian webs and freshness’
Balatarin
To retrieve the Balatarin data in June and July 2009, 2010 and 2011 we created a custom crawler iterating over, and saving, all posts in those periods. The compressed data file contains all the posts (367MB) which were found by crawling Balatarin. Each post is named balatarin_id.html where balatarin_id is the unique ID which can be found in Balatarin’s permalinks.
Each Balatarin post contains a link to an external site. For each post found in the previous step, we retrieved the referenced outlink and stored it as balatarin_id.html. Again, balatarin_id is the unique ID which can be found in Balatarin’s permalinks. In the data file with Balatarin's outlinks (7,9GB) you will find the stored outlinks as referenced in the Balatarin posts.
Voice and expression
The final “health check” in the national web health index is measuring the strength of voice and degrees of expression over a period of three years. We used the stored outlinks referenced in the Balatarin posts in June and July 2009, 2010 and 2011 and queried these URLs with a list of “smelly” language containing fiery, side-taking as well as coded language. See the section “The Iranian web: Voice and expression” for a definition of the terms and the analysis of the data.
The full analysis from 2009, 2010 and 2011 can be found here. The following is a depiction of the data from 2011.
